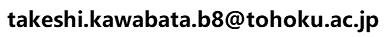HOMCOS : 相同複合体の検索・モデリングサーバ
 タンパク質に対する結合分子の検索
タンパク質に対する結合分子の検索
タンパク質に対する結合分子の検索
タンパク質に対する結合分子の検索
 タンパク質に対する結合分子の検索
タンパク質に対する結合分子の検索
このサービスでは、1本のアミノ酸配列をクエリとして、それと類似したタンパク質と結合している分子を検索します

| database | example |
| UniProt ID | CDK3_HUMAN [link] |
| UniProt AC | Q00526 [link] |
| INSDC protein_id | AAV40830.1 [link] |
| RefSeq protein_id | NP_001249.1 [link] |
入力にあたっての注意事項
| Summary Bars | Full Bars | Site Table | |
| 画面上部に表示されるアイコン | 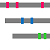 |
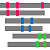 |
 |
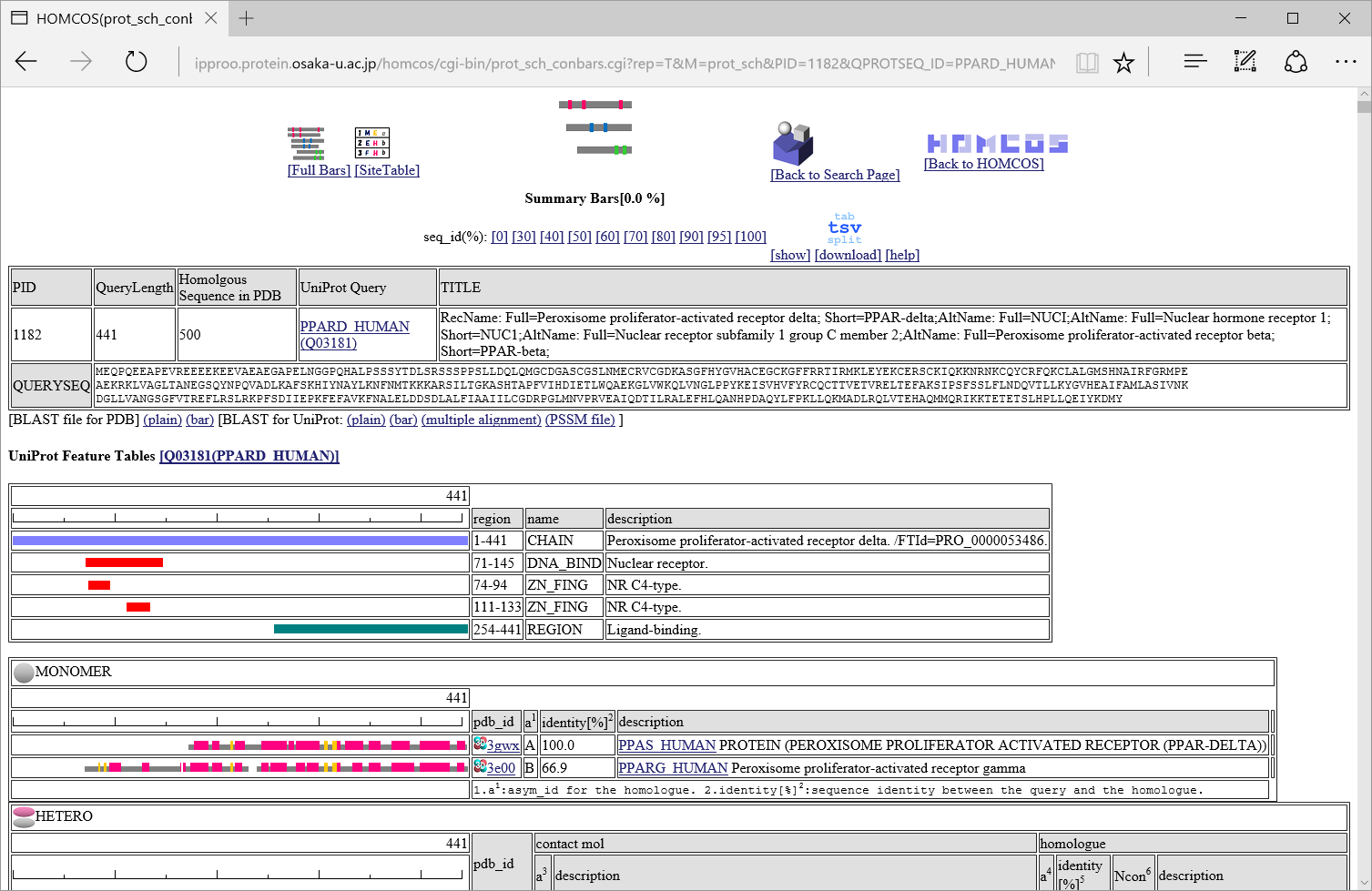
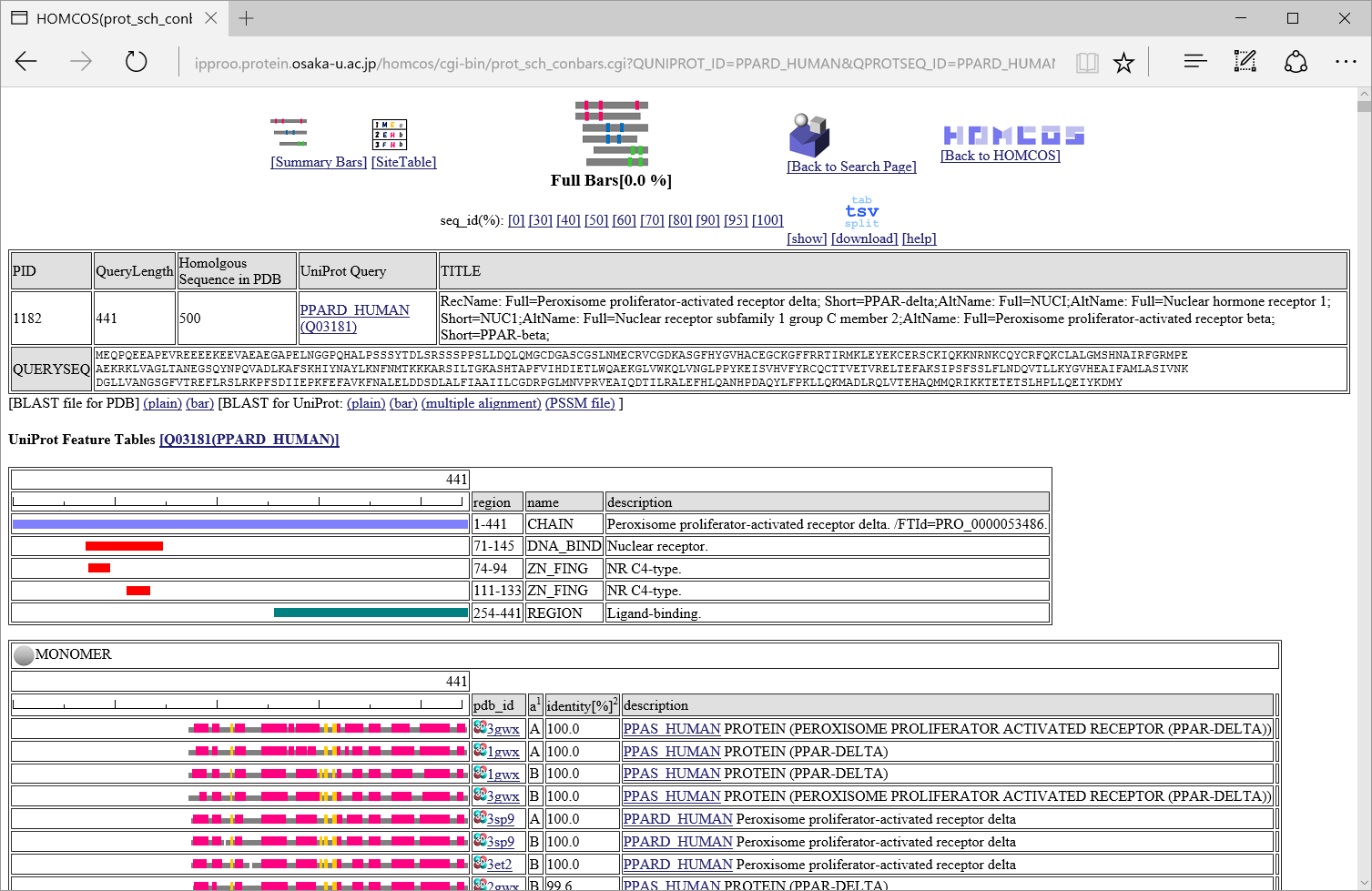
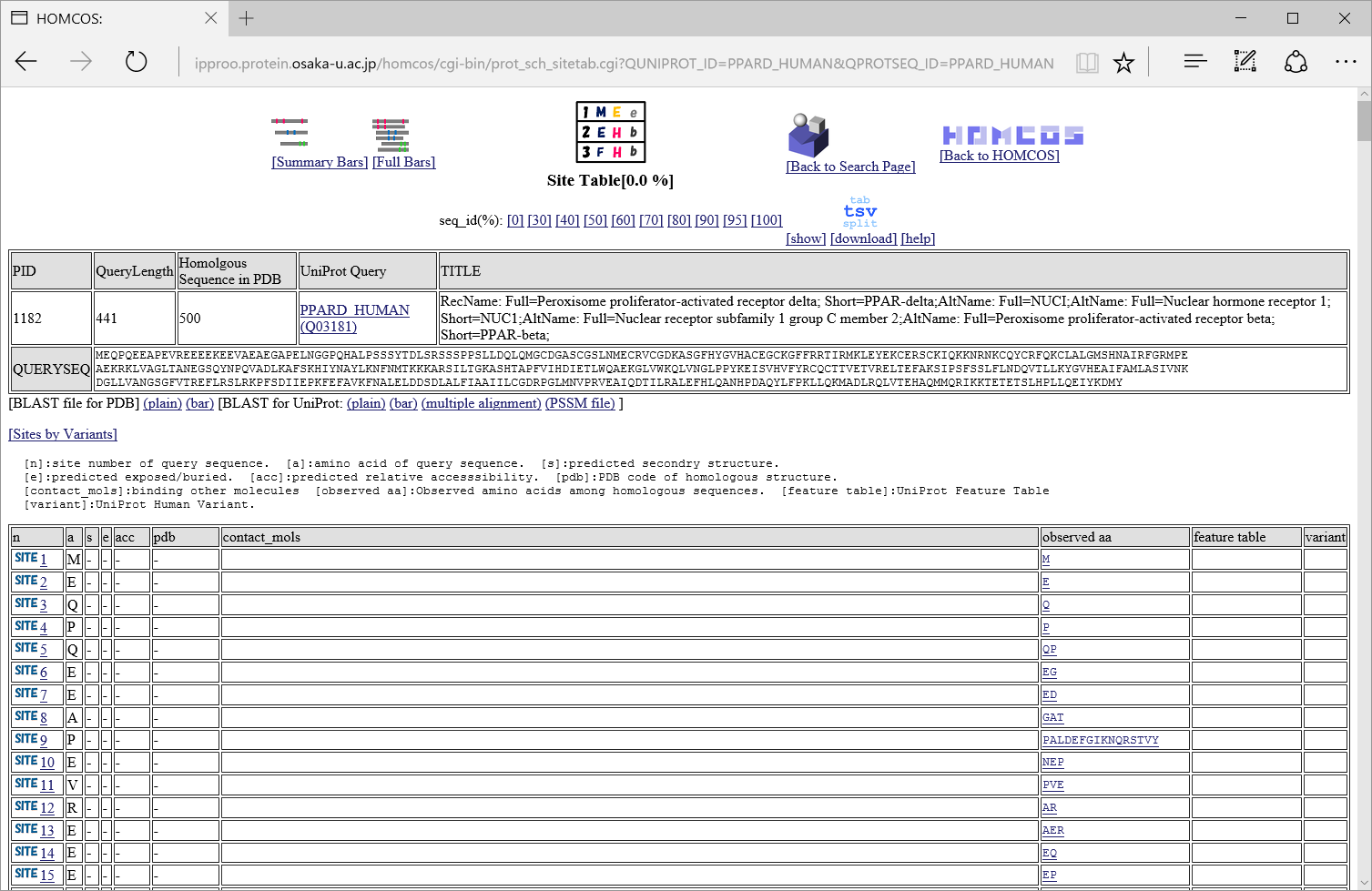
| 説明 | ホモログの構造がアライメントされた領域を色付きのバーで示す表示法。 代表構造だけを示す。 | ホモログの構造がアライメントされた領域を色付きのバーで示す表示法。 すべての相同な構造を示す。 | 1行1サイトのテーブルの形式で結果を表示 |
| 例(PPARD_HUMANをクエリにした場合) |
|
|
|
ウィンドウ上部には、これら三つの表示に共通のリンクや表が表示されています。
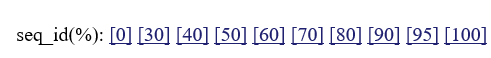 :これらの数字をクリックすることで、相同構造の配列一致率の閾値を変更できます。
:これらの数字をクリックすることで、相同構造の配列一致率の閾値を変更できます。
"Summary Bars"表示について
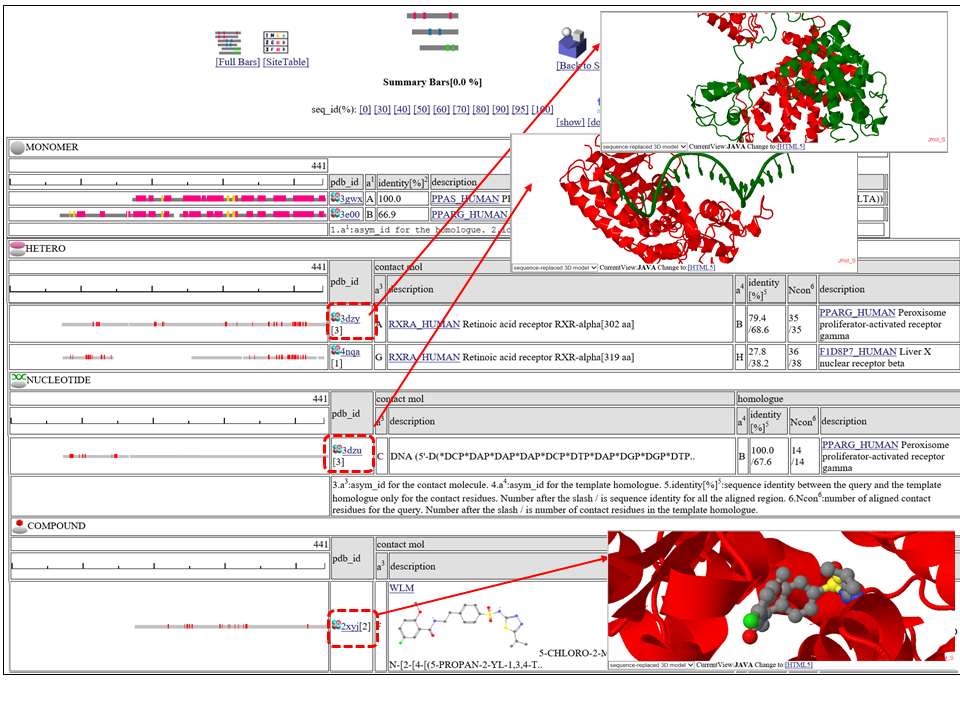


相同な複合体は、7つのクラス(" HETERO", "
HETERO", " NUCLEOTIDE", "
NUCLEOTIDE", " COMPOUND", "
COMPOUND", " METAL", "
METAL", " OTHERPOLY", "
OTHERPOLY", " HOMO",
HOMO",  PRECIPITANT")に分類されています。
PRECIPITANT")に分類されています。
アラインメントされた領域が灰色のバー![]() で表示されます。他の分子とコンタクトしている残基は小さな赤いボックス
で表示されます。他の分子とコンタクトしている残基は小さな赤いボックス![]() で示されます。
で示されます。
 3Dのアイコンをクリックすると、立体構造が表示されます。3Dモデル表示の詳細は別項に説明があります。
3Dのアイコンをクリックすると、立体構造が表示されます。3Dモデル表示の詳細は別項に説明があります。
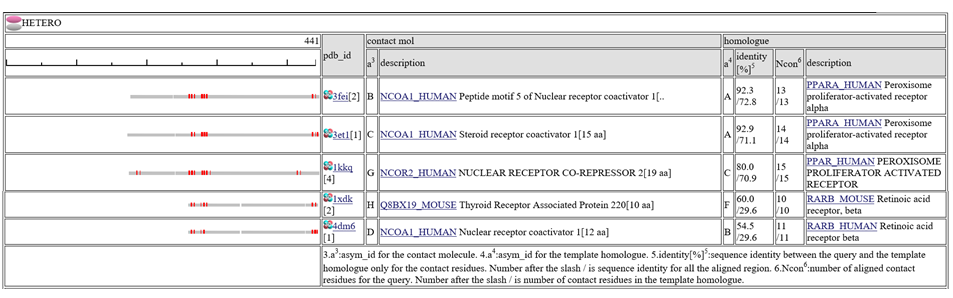
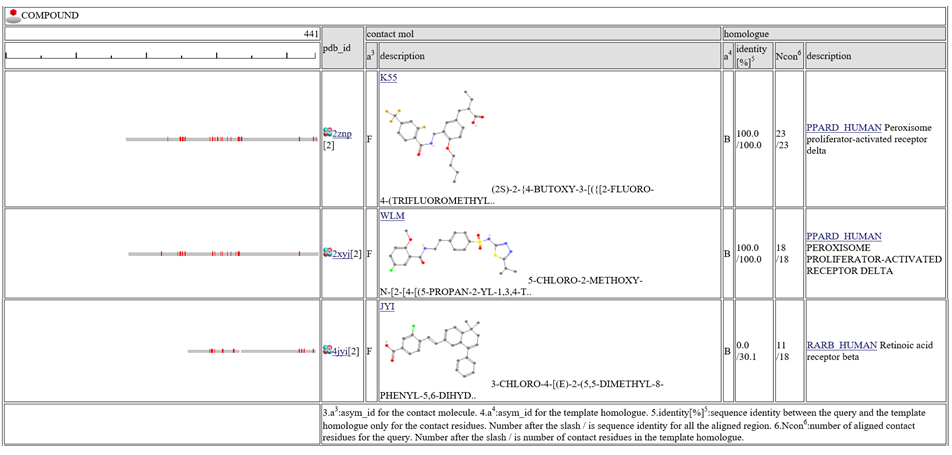
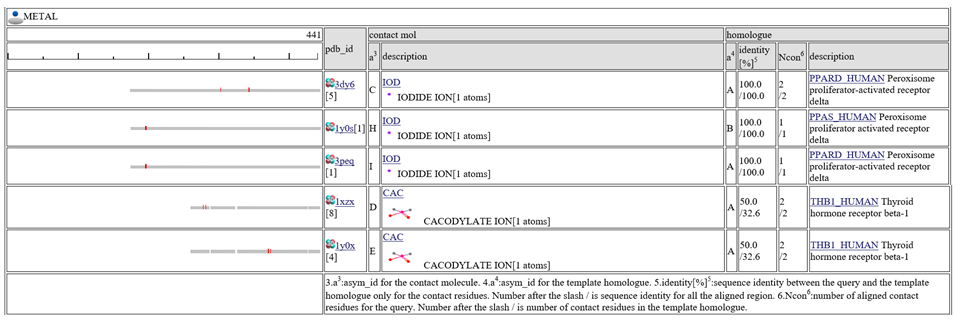
表の中央の列"contact_mol"は、クエリタンパク質のホモログがコンタクトしている分子を表します。表の右の列"homologue"は、クエリタンパク質のホモログを表します。 "identity[%]"という列には、"92.3/72.3"のように二つの配列一致率(sequence identity)が記載されています。最初の数字は、コンタクト部位だけの配列一致率で、次の数字は、アラインメントされた領域全部の配列一致率です。コンタクト部位だけの配列一致率は、予測モデルの質を示す指標として(特に低分子化合物で)有効とされています。 "Ncon"という列には、"13/13"のように、二つのコンタクト部位の数が記載されています。最初の数字は、アラインメントされた領域内のコンタクト部位の数で、二つ目の数字は、鋳型の構造全長のコンタクト部位の数です。もし、最初の数が二番目の数より、かなり小さい場合は、このモデルは、鋳型の複合体のごく一部だけで作られたことになります。
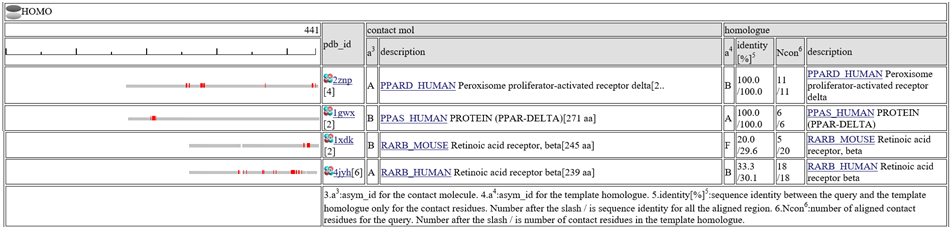

"Site Table"表示について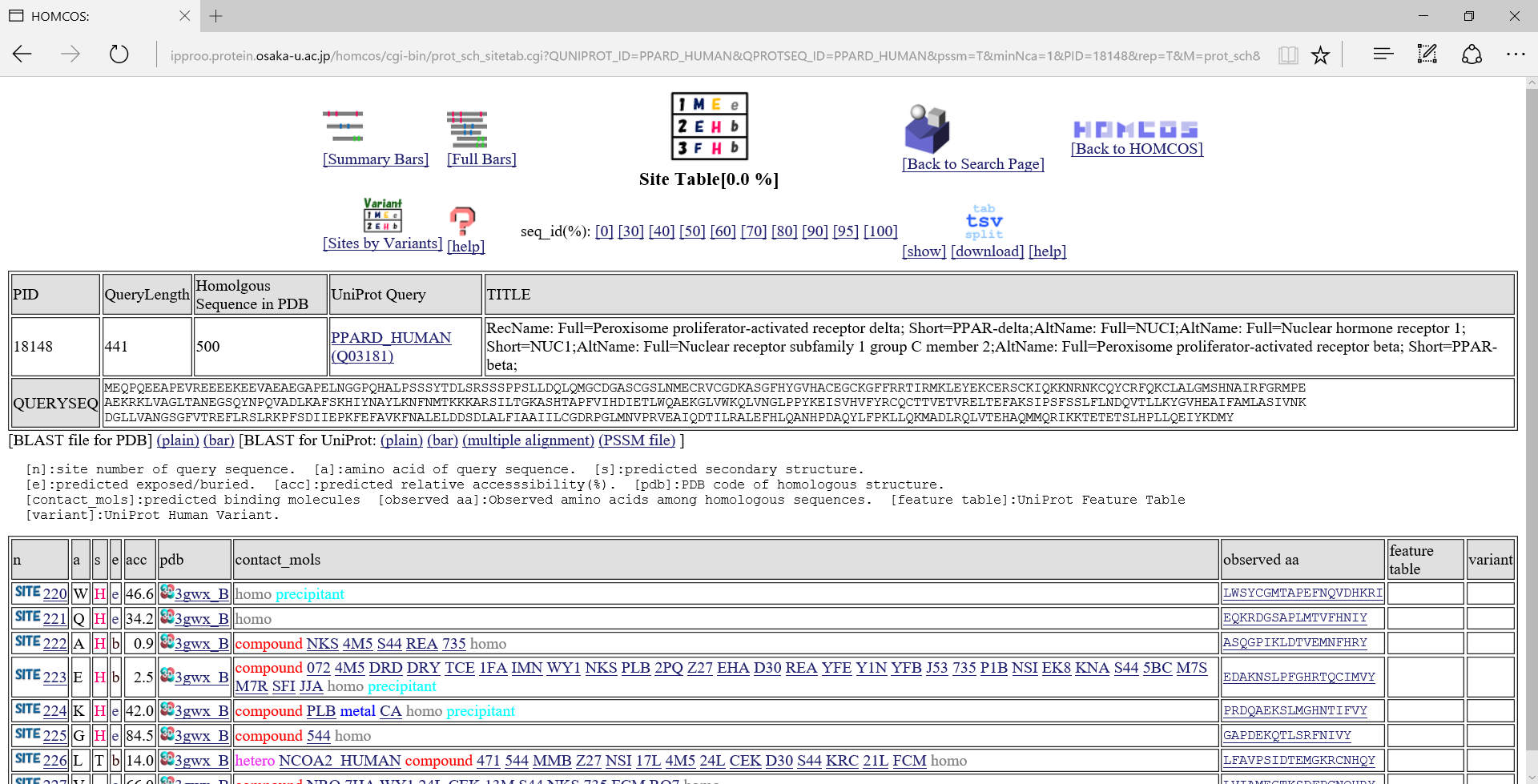
[n]:サイト(部位)の番号. [a]:クエリのアミノ酸配列. [s]:ホモログから予測された二次構造."H":α-ヘリックス、"E":βストランド、"T":ターン.
[e]:ホモログから予測された溶媒露出状態("e":exposed, "b":buried). [acc]:ホモログから予測された溶媒露出度[%]. [pdb]:相同な構造のPDBコード.
[contact_mols]:予測された結合分子 [observed aa]:相同なタンパク質で観察されたアミノ酸. [feature table]:UniProtのFeature Tableの情報
[variant]:UniProtのHuman Variantの情報.
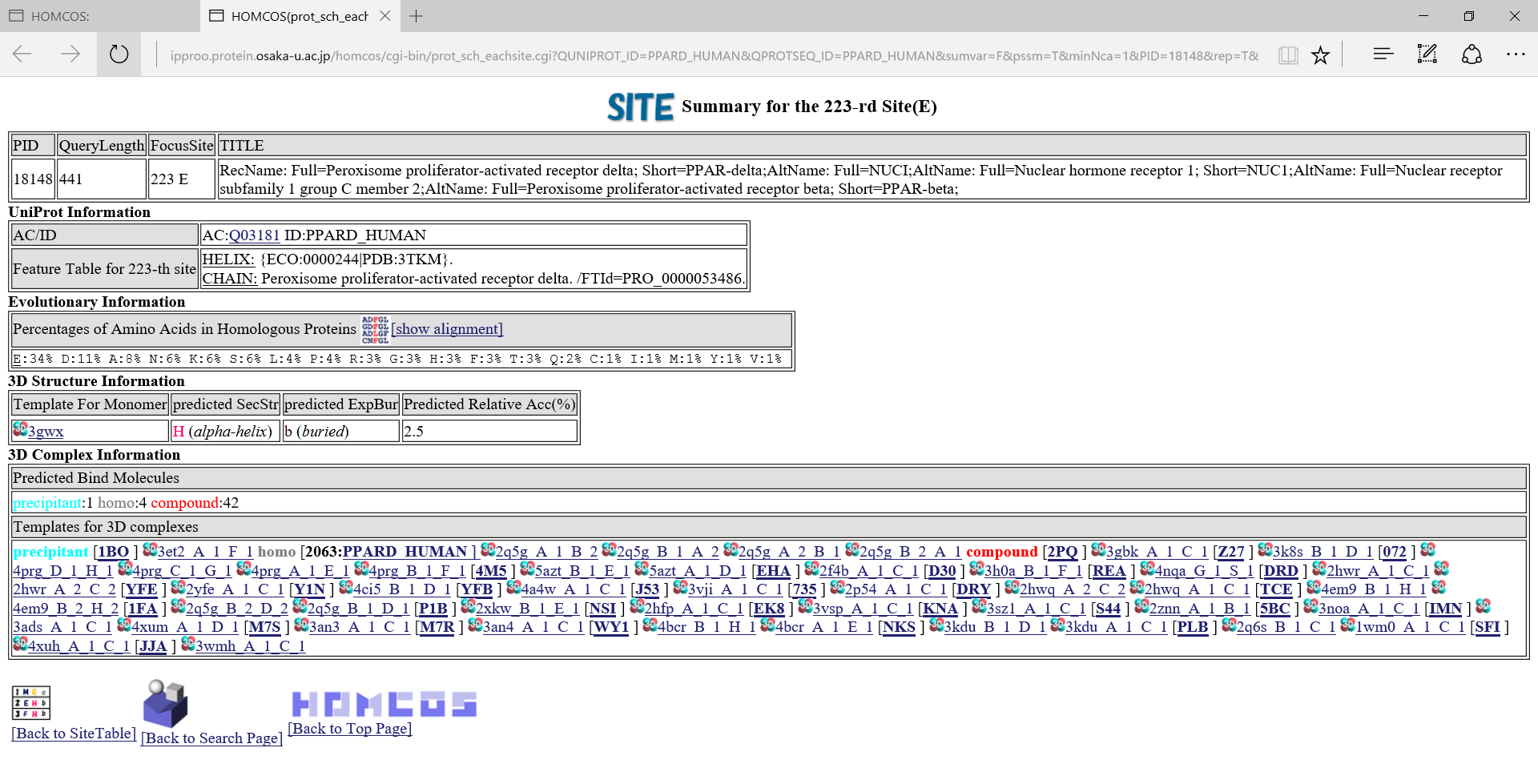
表の左端の列の のアイコンをクリックすると、あるサイトに関する情報をまとめたページが表示されます。以下に例としてPPARD_HUMANの223番目のサイトを示します。
のアイコンをクリックすると、あるサイトに関する情報をまとめたページが表示されます。以下に例としてPPARD_HUMANの223番目のサイトを示します。
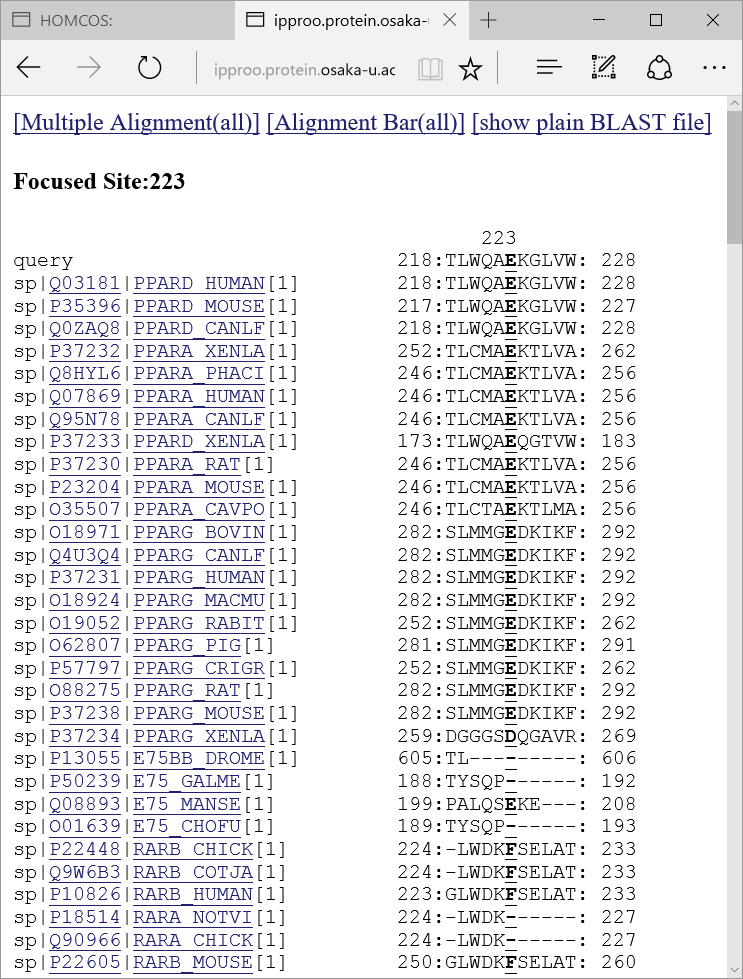
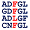 のアイコンをクリックすると、以下のようなこのサイトの周辺だけのマルチプルアラインメントが表示されます。
のアイコンをクリックすると、以下のようなこのサイトの周辺だけのマルチプルアラインメントが表示されます。
"Templates for 3D complexes"の中の のアイコンをクリックすると、以下のように、あるサイトにコンタクトしている複合体のモデル構造が表示されます。
のアイコンをクリックすると、以下のように、あるサイトにコンタクトしている複合体のモデル構造が表示されます。
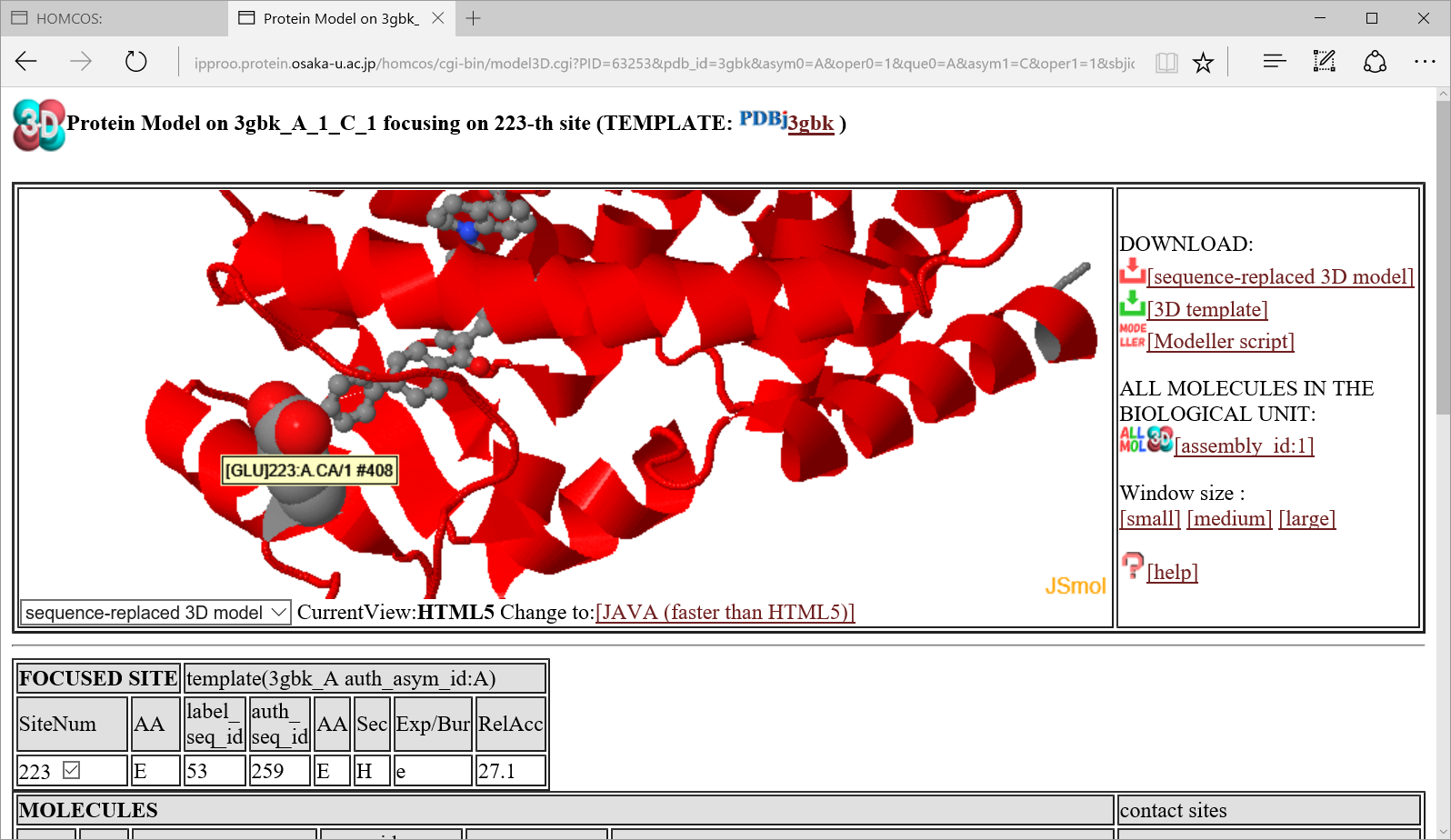 3Dモデル表示の使い方については、別項に説明があります。
3Dモデル表示の使い方については、別項に説明があります。