Contact Molecules for Homologous Proteins | ||||
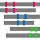 [Full Bars] |
 [SiteTable] |
|
 [Back to Search Page] |
 [Back to HOMCOS] |
 [SupCon3D] |
 [help] |
seq_id(%): [0] [30] [40] [50] [60] [70] [80] [90] [95] [100] |  [show] [download] [help] |
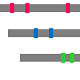
| PID | QueryLength | Homolgous Sequence in PDB | UniProt Query | TITLE |
| 3768 | 422 | 14 | P59595(NCAP_SARS) | RecName: Full=Nucleoprotein ;AltName: Full=Nucleocapsid protein ; Short=NC ; Short=Protein N ; |
| QUERYSEQ |
MSDNGPQSNQRSAPRITFGGPTDSTDNNQNGGRNGARPKQRRPQGLPNNTASWFTALTQHGKEELRFPRGQGVPINTNSGPDDQIGYYRRATRRVRGGDGKMKELSPRWYFYYLGTGPEASLPYGANKEGIVWVATEGALNTPKDHIGTR NPNNNAATVLQLPQGTTLPKGFYAEGSRGGSQASSRSSSRSRGNSRNSTPGSSRGNSPARMASGGGETALALLLLDRLNQLESKVSGKGQQQQGQTVTKKSAAEASKKPRQKRTATKQYNVTQAFGRRGPEQTQGNFGDQDLIRQGTDYK HWPQIAQFAPSASAFFGMSRIGMEVTPSGTWLTYHGAIKLDDKDPQFKDNVILLNKHIDAYKTFPPTEPKKDKKKKTDEAQPLPQRQKKQPTVTLLPAADMDDFSRQLQNSMSGASADSTQA |
|||
 MONOMER
MONOMER 2ofz
2ofz HOMO
HOMO PRECIPITANT
PRECIPITANT